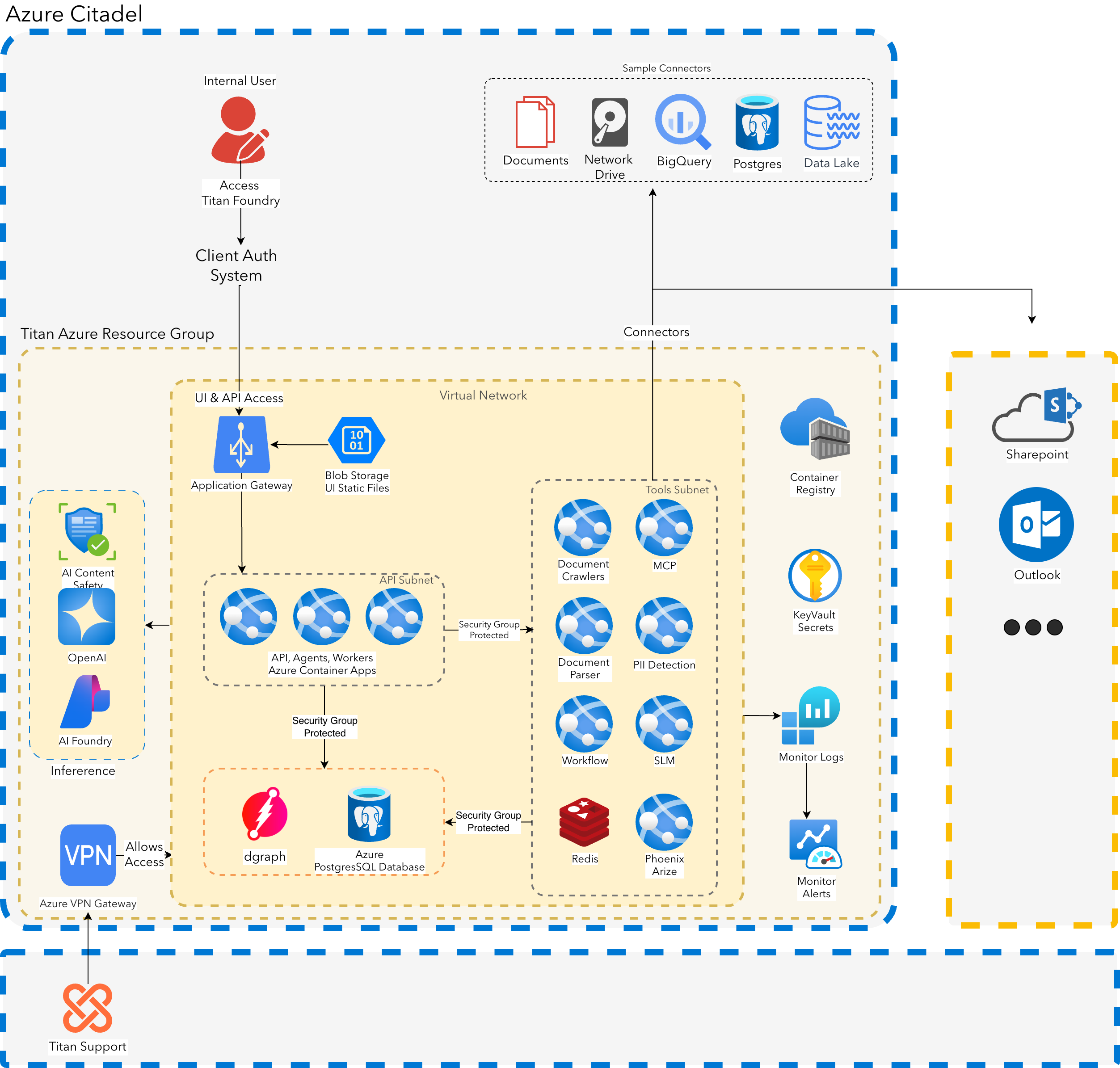
Titan is cloud-agnostic, built on a microservices architecture that leverages containerization with Docker and orchestrated through managed container platforms and Kubernetes. The system is designed to be secure, scalable, resilient, and maintainable.
| Component | Platform | Description |
|---|---|---|
| Primary API | Azure Container Apps | Core ModelHub API serving all client requests. Auto-scales based on traffic. |
| PII Detection Service | Azure Container Apps | Dedicated microservice for detecting and masking personally identifiable information. |
| Document Parsing Service | Azure Container Apps | Dedicated microservice for document extraction and chunking (Docling). |
| Background Workers | Azure Container Apps | Hatchet workers for ingestion pipeline, agent processing, and enrichment tasks. |
| Component | Platform | Description |
|---|---|---|
| PostgreSQL | Azure Database for PostgreSQL — Flexible Server | Relational database for application state, user data, and session management. Encrypted at rest using Microsoft-managed encryption. Automated backups with point-in-time restore enabled. |
| Dgraph | Azure Kubernetes Service (AKS) | Graph database for the knowledge graph — documents, chunks, entities, and relationships. Hosted on AKS for scalability and high-availability. Replicated storage, encrypted at rest and in transit. Regular backups to Blob Storage. |
| Redis | Azure Cache for Redis | In-memory cache for locking semaphores, rate limiting, and session data. |

| Component | Platform | Description |
|---|---|---|
| Web Application | Blob Storage + Azure CDN | React-based SPA hosted on Azure Blob Storage with Azure CDN for global low-latency delivery. |
| DDoS / WAF Protection | Cloudflare + Azure WAF | Edge-level DDoS mitigation and Web Application Firewall with OWASP 3.2 ruleset. |
| Service | CPU | Memory | Instances (min–max) | Description |
|---|---|---|---|---|
| modelhub-api | 1 vCPU | 2 GiB | 1–4 | Core API serving all client requests. Public-facing via Application Gateway. |
| pii-api | 4 vCPU | 8 GiB | 1–2 | PII detection and masking using GliNER (Triton). Internal only. |
| batch-workers | 4 vCPU | 8 GiB | 1–1 | Hatchet workers for document ingestion, parsing, and enrichment. |
| realtime-workers | 4 vCPU | 8 GiB | 1–1 | Hatchet workers for real-time agent and query processing. |
| hatchet-engine | 1 vCPU | 2 GiB | 1–1 | Task orchestration engine (gRPC). Internal only. |
| hatchet-api | 1 vCPU | 1 GiB | 1–1 | Hatchet REST API. |
| hatchet-dashboard | 1 vCPU | 512 MiB | 1–1 | Hatchet workflow monitoring UI. |
| phoenix | 1 vCPU | 2 GiB | 1–1 | LLM observability and tracing UI (Arize Phoenix). |
| phoenix-collector | 1 vCPU | 1 GiB | 1–1 | OpenTelemetry trace collector for Phoenix. Internal only. |
All Container Apps run inside the virtual network via Container Apps VNet integration and pull images from a private Azure Container Registry repository.
| Node Pool | Machine Type | Disk | Nodes (min–max) | Purpose |
|---|---|---|---|---|
| system | Standard_D2s_v3 (2 vCPU, 8 GiB) | 100 GB SSD | 1–2 | Cluster system workloads |
| dgraph | Standard_D8s_v3 (8 vCPU, 32 GiB) | 200 GB SSD | 1–2 | Dedicated graph database (tainted, label-selected) |
The AKS cluster uses Workload Identity, Calico network policies, Managed Prometheus, and Trusted Launch nodes. Maintenance window is Sundays 2–10 AM ET.
All AI model serving runs on a dedicated AKS cluster with autoscaling GPU node pools, exposed through an Application Gateway with WAF (Prevention mode) — TLS and authentication enforced at the gateway.
The cluster runs 5 NVIDIA H100 GPUs always-on (scaling to 8 under load): full GPUs serve primary LLM inference, while MIG-partitioned GPUs host embedding, reranking, NER, and vision services on dedicated slices.
| Machine Type | GPU | Nodes (min–max) | Purpose |
|---|---|---|---|
| Standard_NC40ads_H100_v5 (40 vCPU, 320 GiB) | 1x NVIDIA H100 94 GB | 3–4 | Primary LLM inference (always-on) |
| Standard_NC40ads_H100_v5 (40 vCPU, 320 GiB) | 1x NVIDIA H100 94 GB (MIG-partitioned) | 1–2 | Embedding, reranking, and NER on dedicated GPU slices |
| Standard_NC40ads_H100_v5 (40 vCPU, 320 GiB) | 1x NVIDIA H100 94 GB (MIG-partitioned, large slices) | 1–2 | Vision models and document-conversion workers |
| Standard_NC24ads_A100_v4 (24 vCPU, 220 GiB) | 1x NVIDIA A100 80 GB | 0–1 each | Fallback GPU capacity (scales to zero when idle) |
Services hosted on the inference cluster:
| Service | Port | Description |
|---|---|---|
| vLLM (medium) | 8000 | Primary LLM inference |
| Titan SLM | 8003 | Custom small language model |
| TEI Embedding | 8080 | Text Embeddings Inference |
| TEI Reranker | 8001 | Cross-encoder reranking |
| Triton | 8002 | Model serving (PII / NER) |
| Docling | 5000 | Document parsing and extraction |
| vLLM (MinerU) | 8004 | OCR and table-structure extraction |
| vLLM (Granite Vision) | 8005 | Image and chart description |
| vLLM (dots.ocr) | 8006 | Document OCR |
Titan implements security at every layer of the stack — from the network edge through the AI response. No single layer is trusted in isolation; each reinforces the others.
| Control | Description |
|---|---|
| Cloudflare WAF | Web Application Firewall in Prevention mode with OWASP 3.2 ruleset. Detects and blocks SQL injection, XSS, command injection, and path traversal at the edge before traffic reaches application infrastructure. |
| Cloudflare DDoS Protection | Always-on volumetric and application-layer DDoS mitigation. Absorbs attack traffic at Cloudflare's global network, keeping origin infrastructure available during attacks. |
| SSL/TLS Everywhere | All traffic encrypted in transit. TLS termination at the load balancer with HSTS enforcement (max-age=31536000; includeSubDomains). No plaintext HTTP connections accepted in production. |
| Control | Description |
|---|---|
| VNet Network Isolation | All application components run within a private Virtual Network (VNet). Databases, caches, and internal services are not exposed to the public internet. |
| Subnet Segmentation & NSGs | Network Security Groups enforce least-privilege traffic between subnets. Only necessary ports and protocols are permitted between tiers (e.g., API → Database, Worker → Redis). |
| Private Endpoints | PostgreSQL, Azure Cache for Redis, and Blob Storage are accessed via Private Endpoints (Azure Private Link) and private IP — traffic stays on Microsoft's backbone and never traverses the public internet. |
| Microsoft Defender for Cloud | Continuous security posture assessment (CSPM), vulnerability detection, and threat protection across all Azure resources. Includes Defender threat protection for Azure Database for PostgreSQL, Storage, and Virtual Machines. |
| CrowdStrike Falcon + MDR | Endpoint Detection and Response (EDR) deployed across all compute infrastructure — AKS nodes, Container Apps instances, and any supporting VMs. Falcon sensors monitor process execution, network connections, and file activity to detect and block malware, ransomware, and lateral movement. Supplemented by CrowdStrike Falcon Complete MDR (Managed Detection and Response) — CrowdStrike's Tier 3 security analysts monitor the environment 24/7, triaging alerts, investigating threats, and taking response actions (containment, remediation) within the permissions granted. This provides SOC-level coverage without maintaining an in-house security operations center. |
| Malware Scanning | Microsoft Defender for Storage scans uploaded objects for malware. The ingestion pipeline enforces fail-closed logic — files are only processed after an explicit clean scan result. Infected files are quarantined and rejected. |
| Control | Description |
|---|---|
| Auth0 Authentication | Industry-standard OAuth 2.0 / OpenID Connect via Auth0. JWT tokens validated using RSA public keys with automatic JWKS rotation and caching. Multi-factor authentication (MFA) supported. |
| Role-Based Access Control (RBAC) | Role hierarchy (admin, supervisor, user) with permission checks enforced at the API layer. Role assignment is restricted — only admins can escalate privileges. |
| Email Allowlist | Optional email-based access control restricts which users can authenticate. Supports bulk import and per-entry enable/disable for onboarding control. |
| Rate Limiting | Distributed Redis-backed sliding window rate limiter with atomic Lua operations. Per-connector and per-endpoint limits prevent abuse and protect upstream APIs. |
| CORS Policy | Origin allowlisting restricts which domains can make cross-origin API requests, preventing unauthorized browser-based access. |
| Security Headers | X-Content-Type-Options: nosniff, X-Frame-Options: DENY, and Strict-Transport-Security headers protect against MIME sniffing, clickjacking, and protocol downgrade attacks. |
| Input Validation | Pydantic schema enforcement on every API endpoint. All request bodies, query parameters, and path parameters are validated with type checks, length constraints, and regex patterns before reaching business logic. |
| HTML Sanitization | All user-provided HTML content is sanitized using nh3 (Rust-based). Scripts, event handlers, javascript: and data: URLs are stripped. Filenames are sanitized with XSS detection before path operations. |
| File Upload Validation | Magic byte detection prevents MIME type spoofing. Blocked file types (executables, scripts, archives) are rejected. OOXML structure validation verifies Office document integrity. Configurable file size limits enforced. |
| Control | Description |
|---|---|
| Snyk | Continuous code vulnerability scanning integrated into the development workflow. Identifies known vulnerabilities in application code and dependencies. |
| Bandit | Static security analysis for Python runs in CI on every pull request. Detects hardcoded secrets, insecure function usage, and common security anti-patterns. |
| pip-audit | Dependency vulnerability scanning in CI. Distinguishes between fixable and unfixable vulnerabilities — PRs are blocked when patches are available. |
| Exact Dependency Pinning | All dependencies pinned to exact versions (==) in pyproject.toml, including critical transitive dependencies. Prevents supply chain attacks via unexpected version resolution. |
| Pre-Commit Security Gates | Automated format, lint, security scan, and dependency audit checks run before every commit. Code that fails any gate cannot be committed. |
| Control | Description |
|---|---|
| Encryption at Rest | All data encrypted at rest using Microsoft-managed encryption keys — PostgreSQL, Blob Storage, and managed disks. Customer-managed keys (CMK) via Azure Key Vault available for additional control. |
| Encryption in Transit | TLS enforced on all connections: client → API, API → PostgreSQL, API → Redis, worker → Blob Storage. No unencrypted internal communication. |
| PII Detection & Masking | PII middleware intercepts agent inputs and outputs. Tier 0/1 PII (SSNs, credit cards) is rejected. Tier 2 PII (names, emails, phones) is masked with cryptographically random tokens before reaching the LLM and unmasked on return. |
| Secrets Management | Sensitive configuration (OAuth credentials, API keys, connector secrets) encrypted at rest using Fernet symmetric encryption. Secrets are masked as "********" in API responses. Azure Key Vault provides additional key management with RBAC access control, versioning, and purge protection. |
| Session Security | PostgreSQL-backed token blocklist with per-session JTI tracking. Supports session revocation, logout-everywhere, and automatic expired session cleanup. |
This layer addresses threats unique to AI-powered applications — prompt injection, hallucination, data leakage, and model misuse.
| Control | Description |
|---|---|
| LLM Vulnerability Scanning | Automated adversarial testing using garak, an LLM vulnerability scanner. Custom generator module runs targeted scans against the deployed API to identify prompt injection, jailbreak, and data exfiltration vulnerabilities. |
| Input Security Service | Multi-layer prompt injection defense. Fast Aho-Corasick pattern matching detects known attack patterns (model disclosure probes, system prompt extraction). A secondary LLM-based semantic analysis layer catches novel prompt injection and context manipulation attempts. |
| Security Judge | A dedicated LLM evaluates agent responses before they reach the user. Flags responses that leak system internals, contain inappropriate content, or violate security policies. Configurable confidence threshold controls sensitivity. |
| PII Middleware | Intercepts all LLM inputs and outputs. PII is masked before the LLM sees the prompt and unmasked in the response. Mask tokens persist across multi-turn conversations, ensuring no PII is sent to external models. |
| Topic Guardrails | Constrains the agent to stay within its configured domain. Off-topic queries (e.g., asking a compliance agent about cooking recipes) are detected and redirected, preventing misuse of the system. |
| Groundedness Checks | LLM-based validation that every claim in the response is grounded in retrieved evidence. Unsupported claims are identified and removed before the response is delivered. Configurable to skip when citation confidence is already high. |
| Evidence Sufficiency Gate | When the knowledge graph search returns insufficient supporting documents, the system refuses to speculate. Instead of generating a low-confidence answer, it returns a standardized response indicating that it cannot answer with adequate supporting evidence. |
| Control | Description |
|---|---|
| Sentry | Real-time error tracking and anomaly detection. Custom event filtering, transaction monitoring, and performance profiling. User context binding traces errors to specific sessions. |
| Structured Logging & Audit Trail | Every request carries a correlation ID that flows through the entire pipeline — API, workers, agents, and knowledge graph operations. User identity is bound to log context via contextvars for full audit traceability. |
| OpenTelemetry Tracing | Distributed tracing with OpenTelemetry for end-to-end request observability. Custom span processors track LLM calls, tool executions, and agent decision points. Supports OTLP export for integration with observability platforms. |
| Security Alerting | Automated alerts for failed authentication attempts, privilege escalation, critical resource deletion, and policy changes. SMS escalation for Sev0/Sev1 events. All security events tagged with SOC2 control references. |
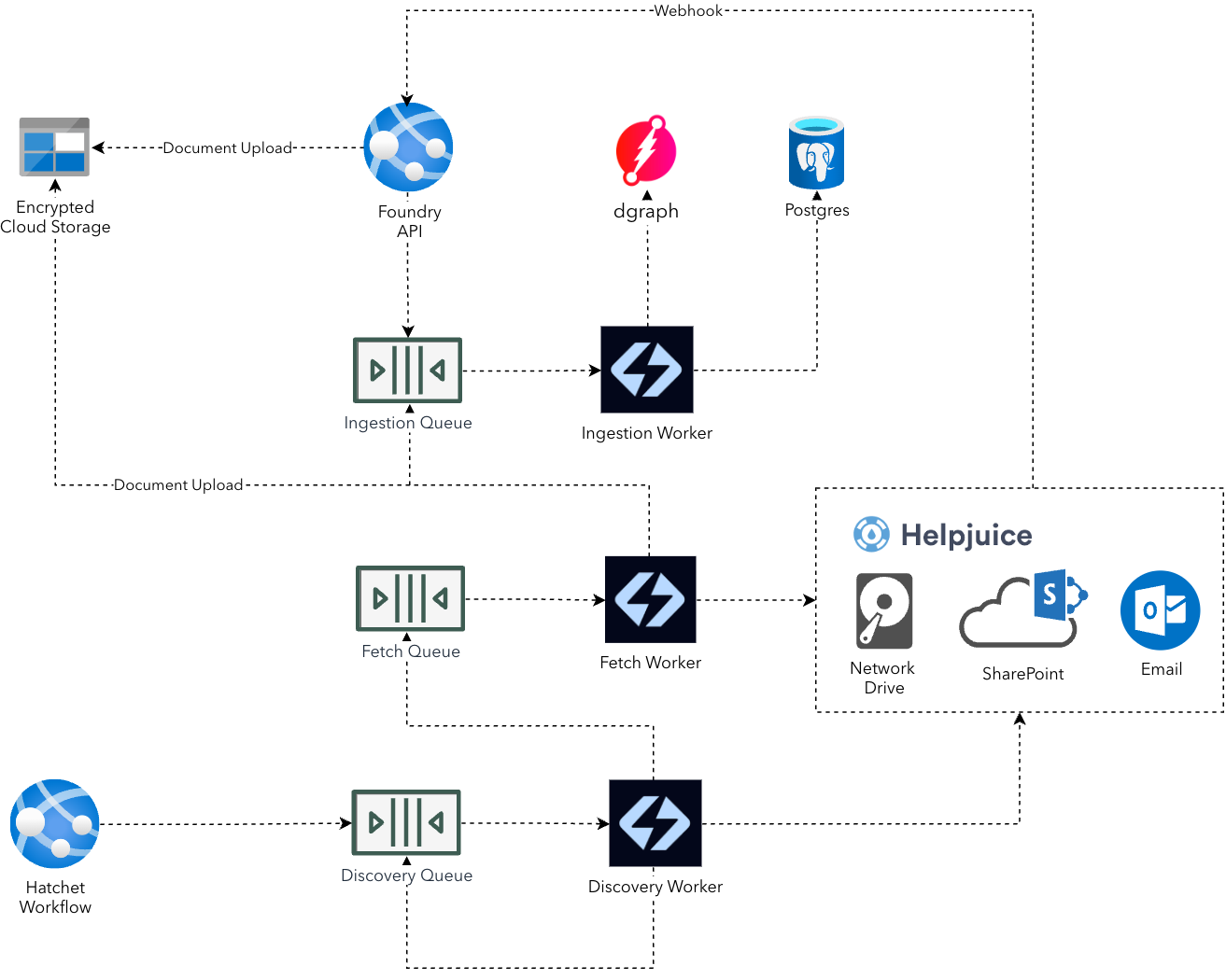
The ingestion process consists of several key components:
| Component | Description |
|---|---|
| Hatchet Workflow | Directed Acyclical Graph (DAG) workflow, providing durable, scalable worker orchestration with automatic retries and exponential backoff. |
| Orchestrator | Manages the full discovery-fetch-ingest lifecycle, triggered on a schedule (daily) or ad-hoc per connector. Monitors pipeline progress and waits for idle state before completing. |
| Discovery Queue | PostgreSQL queue for queueing up document discovery for a Titan Connector. |
| Discovery Worker | Durable Hatchet worker responsible for crawling configured sources (e.g., HelpJuice, Blob Storage, network drives), generating stable document IDs, and publishing fetch tasks. Supports recursive directory traversal and rate limiting. |
| Fetch Queue | PostgreSQL queue for queueing the download of discovered documents. |
| Fetch Worker | Durable Hatchet worker responsible for fetching document content from sources, uploading to Blob Storage, calculating content hashes for deduplication, and publishing ingestion tasks. |
| Ingestion Queue | PostgreSQL queue for queueing document ingestions. |
| Ingestion Worker | Durable Hatchet worker performing deduplication, malware scanning, document parsing, chunking, embedding generation, PII detection, and graph insertion. |
| Enrichment Worker | Post-ingestion Hatchet worker that extracts entities and relationships from document chunks using a local LLM, builds canonical entity graphs, and links relationships with confidence scores. |
| Summarization Worker | Post-ingestion Hatchet worker that generates document summaries using a local LLM, running in parallel with enrichment. |
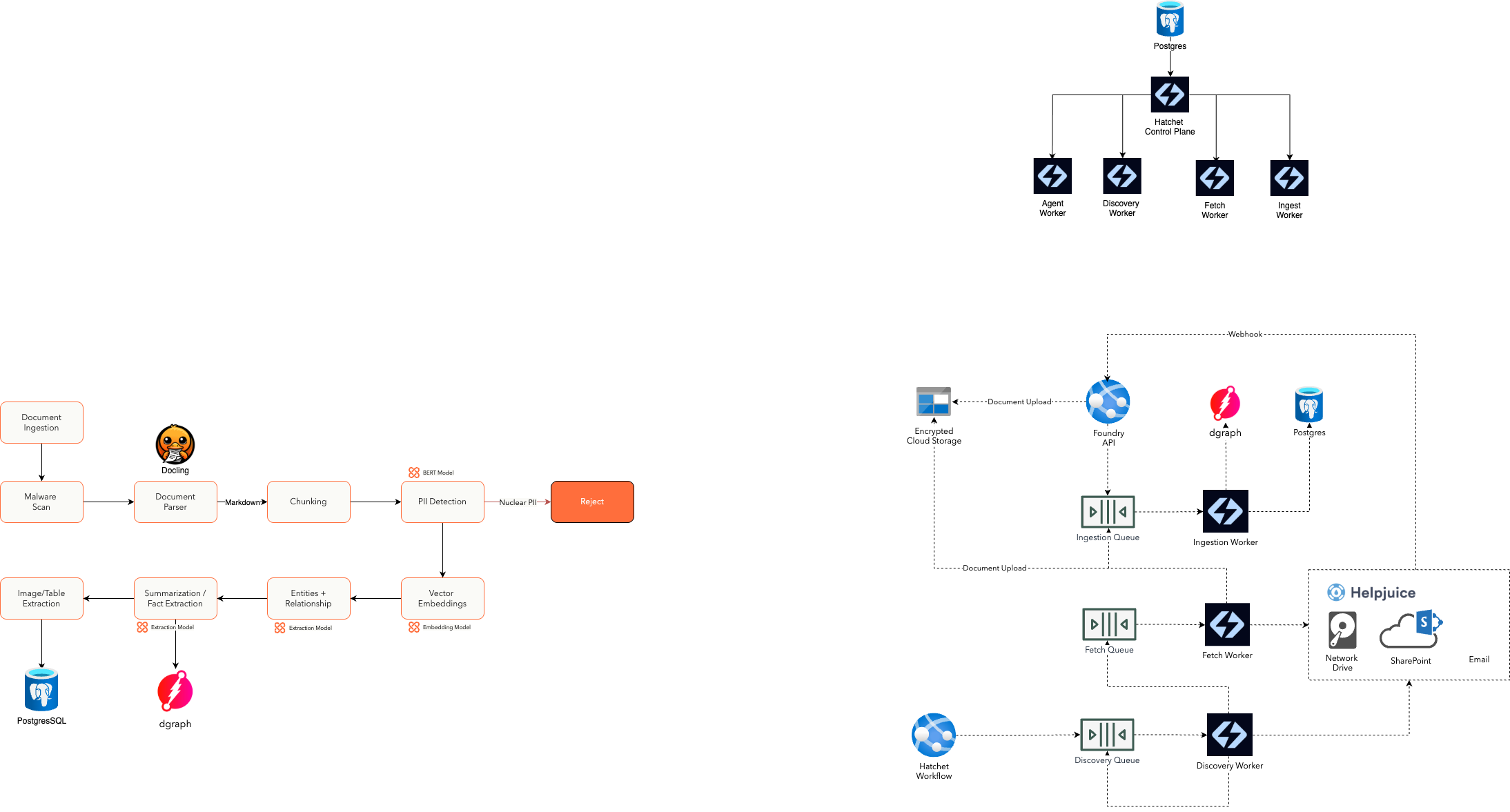
Orchestrator triggers the Discovery Worker for each configured connectorFetch Worker retrieves the document contentIngestion Worker checks for existing copies before processingDocument Parser (Docling) processes the documentdgraph graph database with metadata and embeddingsRecord node is created with source metadata and access control informationEnrichment Worker extracts structured knowledgeSummarization Worker generates a document summaryRecord node in the graphTier 0 PII is rejected (Credit Card Numbers)Tier 1 PII (SSN, IDs, etc) are rejected in the chat experience and masked in the agents.Tier 2 PII (Full Names, Email Addresses, Phone Numbers, etc) masked.Default PII Tier Classifications
| Tier 0 PII | Tier 1 PII | Tier 2 PII |
|---|---|---|
| Credit Card Numbers | Social Security Numbers | Full Names |
| Medical IDs | Phone Number | |
| Passport | URLs | |
| Driver's Licenses | Date of Births | |
| Addresses | ||
| Bank Account Numbers |
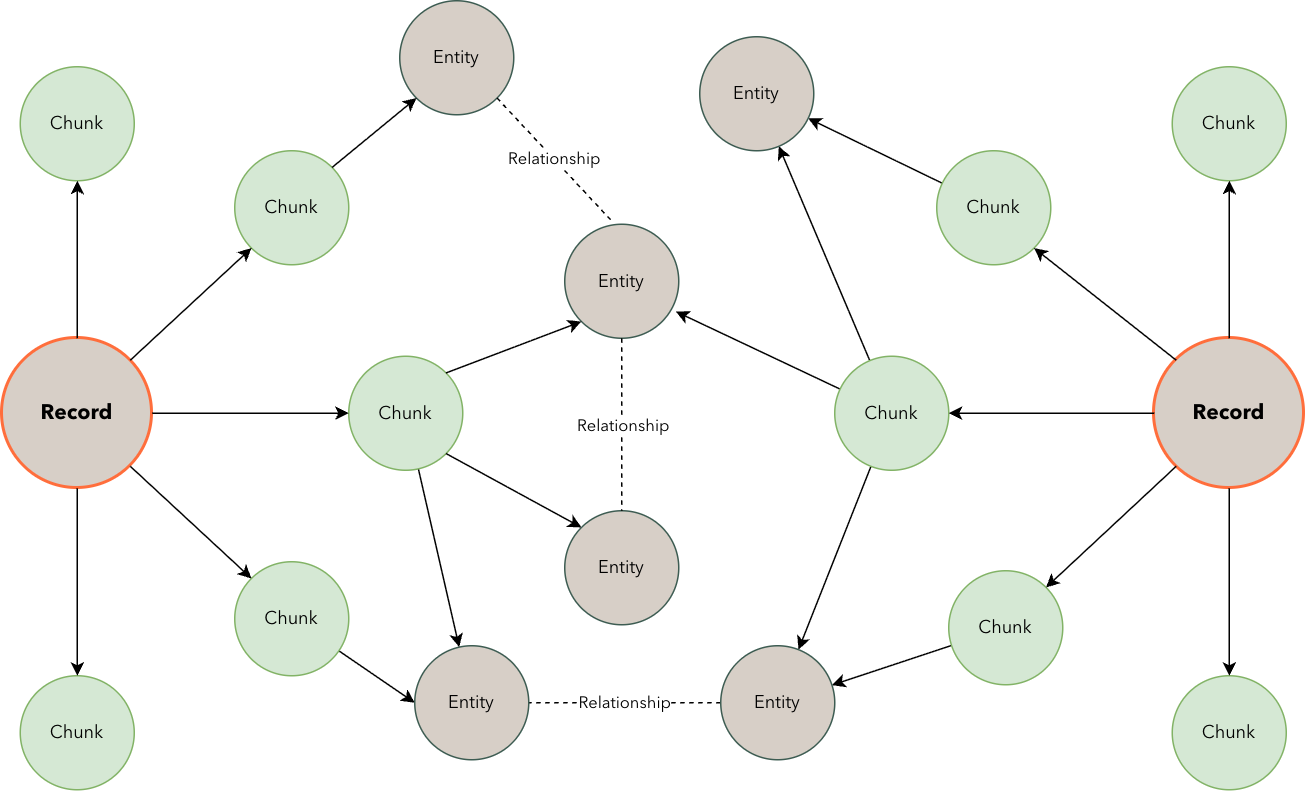
Record node in the graph.Record nodes contain metadata such as:source: URL or file path of the documenttimestamp: Ingestion timestampsummary: Generated summary of the documentpermissions: Access control informationChunk nodes for efficient retrieval.Chunk node contains:text: The text content of the chunkembedding: Vector representation for semantic searchmetadata containing context such as page number, section title, etckeywords: Extracted keywords for indexingEntity nodes.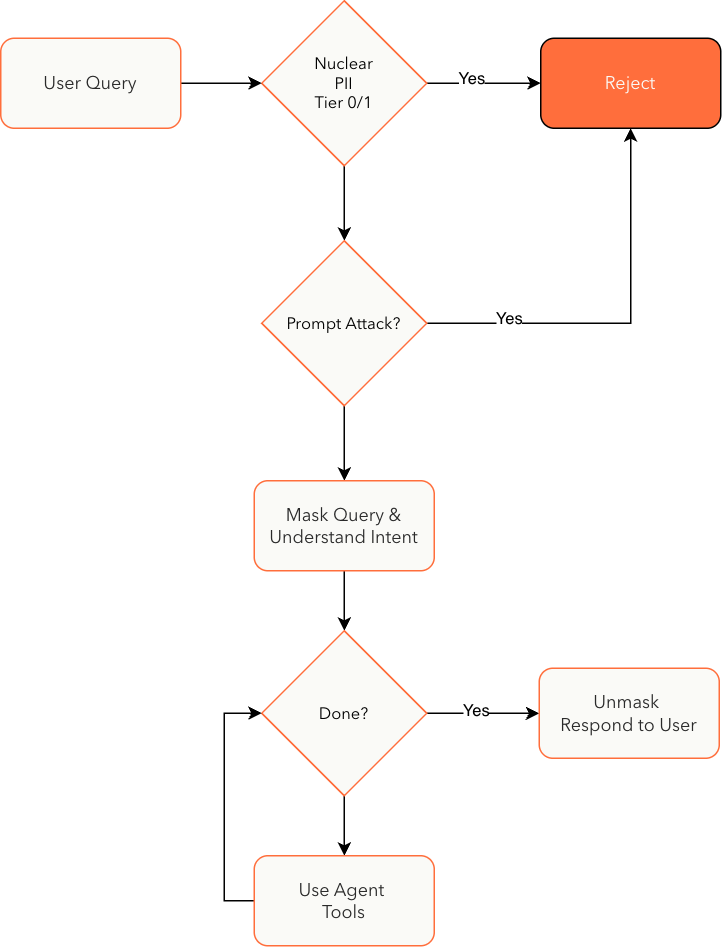
Titan is built on the principle that every AI-generated answer must be traceable, verifiable, and auditable. Users should never have to take an answer on faith — they should be able to see why the system answered the way it did, what sources it used, and how confident it is.
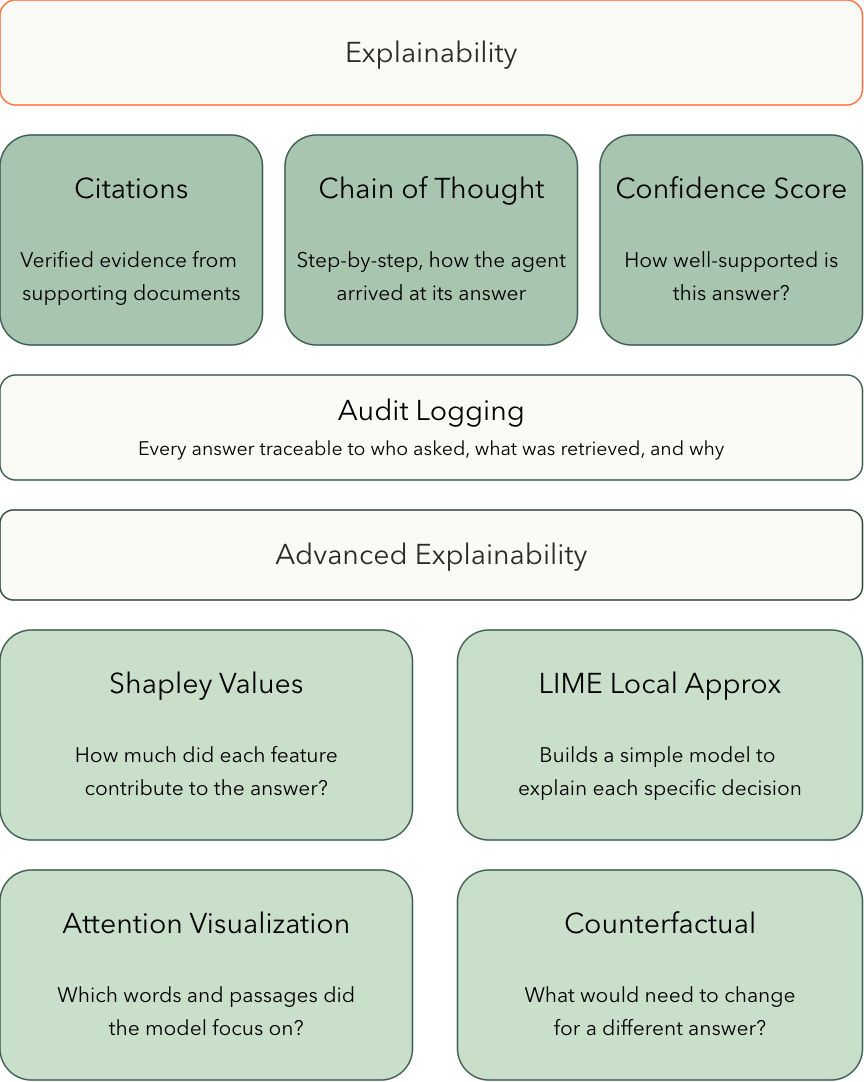
Every answer includes citations linking claims back to specific source documents. Citations are not simply appended — they go through a multi-stage verification process to ensure they are genuine and relevant.
Each response includes a confidence indicator based on citation strength:
| Scenario | Confidence | Meaning |
|---|---|---|
| Citations found and verified | High (0.9) | Answer is well-supported by source documents |
| Search performed, no results | Low (0.5) | Limited assurance — answer may rely on general knowledge |
| No search performed | Moderate (0.7) | General knowledge answer, no retrieval needed |
The agent's decision-making process is captured at each step — what tools were called, what the agent was thinking, and how it arrived at the final answer. This chain-of-thought reasoning is stored alongside the response and will be available to users, providing full transparency into the agent's reasoning process.
Beyond citations and chain-of-thought, Titan is actively investigating techniques from the field of Explainable AI (XAI) to give users deeper insight into why the system produced a particular answer and how much each piece of evidence contributed.
Shapley values, originally from cooperative game theory, provide a mathematically principled way to attribute an outcome to individual contributors. Applied to Titan's agent pipeline, Shapley values would quantify each retrieved document's contribution to the final answer — answering the question: "If this document hadn't been retrieved, how would the answer change?"
This goes beyond binary citation (cited vs. not cited) to provide a continuous importance score for each source, helping users understand which documents were most influential and which were merely corroborative.
LIME generates human-readable explanations by approximating model behavior locally around a specific prediction. In Titan's context, LIME would explain individual agent responses by perturbing inputs (e.g., removing paragraphs from retrieved context) and observing how the answer changes.
This would surface explanations such as: "The answer focused on Q3 revenue primarily because of paragraphs 2 and 5 from the quarterly report — removing them shifts the answer toward Q2 data."
Attention visualization surfaces which parts of the input the model focused on when generating each part of its response. Titan is exploring exposing attention patterns from the local small language model (SLM) using libraries such as BertViz and TransformerLens, as well as token-level log probabilities from cloud LLM providers.
The goal is an interactive view where users can see which words and passages in the source documents the model attended to most heavily, providing an intuitive visual explanation of the reasoning process.
Counterfactual explanations answer the question: "What would need to be different for the answer to change?" For example: "If the policy document had not mentioned the 30-day exception, the agent would have answered that no exceptions exist."
This technique helps users build trust by making the boundaries of the system's reasoning visible — showing not just what the answer is, but what conditions would produce a different one.
Titan uses RAGAS (Retrieval Augmented Generation Assessment), an industry-standard framework for measuring the quality and accuracy of AI generated answers. Evaluation metrics ensure that responses are not only relevant but also grounded real data.
RAGAS evaluations are run internally on a regular basis to monitor system performance and identify areas for improvement.
Faithfulness Measures whether the answer is supported by the retrieved documents. A high faithfulness score means Titan isn't "making things up" — every claim in the response can be traced back to your source data. This is critical for compliance and trust.
Example: If Titan says "Q3 revenue was $4.2M," that figure must appear in one of the retrieved documents.
Answer Relevancy Evaluates how well the response actually addresses the user's question. A high score means Titan understood what was being asked and provided a focused, on-topic answer rather than tangential information.
Example: If a user asks "What are our data retention policies?", the answer should directly address retention — not general security policies.
Context Precision Measures whether the documents retrieved to answer the question were actually relevant. High precision means Titan is pulling the right documents, not cluttering its reasoning with unrelated content that could dilute answer quality.
Context Recall Evaluates whether Titan found all the relevant documents needed to fully answer the question. High recall means important information isn't being missed, reducing the risk of incomplete answers.